3.28 机器学习与认知计算所第一次组会问题记录
1.Question 1 Yolo 算法
感谢参考 https://blog.csdn.net/zijin0802034/article/details/77685438
https://blog.csdn.net/qq_34199326/article/details/84109828
1.1 bounding box(anchor box)的大小问题?
在yolo算法进行执行时,第一步是进行对图片的resize( 448 × 448 ) 和 grid 网格的划分。然后,通过不同的网格来计算bounding box的五项值,分别为目标点中心点(x,y),box的长宽(w,h),还有置信度(confidence)。这其实在yolo1中是一个回归问题。回归计算出这些值。一般来说bounding box 的多少是前期设定的。这么做是为了避免一个grid中有多个object的中心点。执行后会生成 一个多维矩阵。这些都比较能够简单理解。

但是我们的问题是
- 如何区别不同的anchor box ?
- box的大小是训练得到的还是提前设好的长宽比例?
直观的解释这个问题,可以看一张网上运行yolo的图,可以直接发现,其中box并没有一定比例。(难道说那个比率也是学习出来的?)

但是为什么anchor box 提出的时候用的是两个横纵比不一样的图呢,其实我个人认为就是在区分有两个box,而这两个box本质上是没有区别的。
而且我们为啥会想到box是提前设好长宽比例的呢,其实是因为我们混淆了滑动窗口检测和yolo的区别。滑动窗口被替代的注意原因就是计算量太多,而且box大小不一致。所有在yolo中这些值都是回归计算,通过loss函数惩罚算出来的。具有比较好的鲁棒性。

但是也不得不说,yolo算法只有两个box也算是它的一个缺点,对那种靠的很近的多目标检测就比较有问题。
2.Question 网络训练问题
2.1 Batch size 对训练的影响
其实这个问题我以前自己实践的时候也从来没有思考过,但是经过景老师的一番话语,真的可以说是一句点醒梦中人了。
对于一个深度神经网络来说,为了让网络好训练一些,我们一般都会采用多种正则化方面,分batch训练就是其中一个
当然对于比较大的batch网络的训练就会比较平稳,但是batch过小loss就会出现震荡。
2.2 注意网络可对比性问题
改变一个参数或者超参,很多时候是不存在可比性的(这里有问题欢迎探讨)
3.Question 可解释性
3.1网络可解释性研究重点的变化
现在的很多图像识别网络已经能够具备两个都有的功能,即一方面能够进行分类,指出图片中的信息,另一方面也能够对目标进行定位
- 以往的LRP,SA等是对重要决策信息在图像上进行反馈。来验证网络为什么好,是pixel像素级别的
- CAM,grad-CAM 是通过GAP的定位能力来进行重要决策信息的位置热力图还解释网络,是单图片级别的
我的个人想法是将单图片级别上升到多图片的类。也是受人脸识别的三元组启发。

我们也可以对这么这个网络中的多个类中的多个图片进行建立三元组,然后分析出他们直接有什么共同特征都被这个网络识别到了,通过这种来解释我们的网络
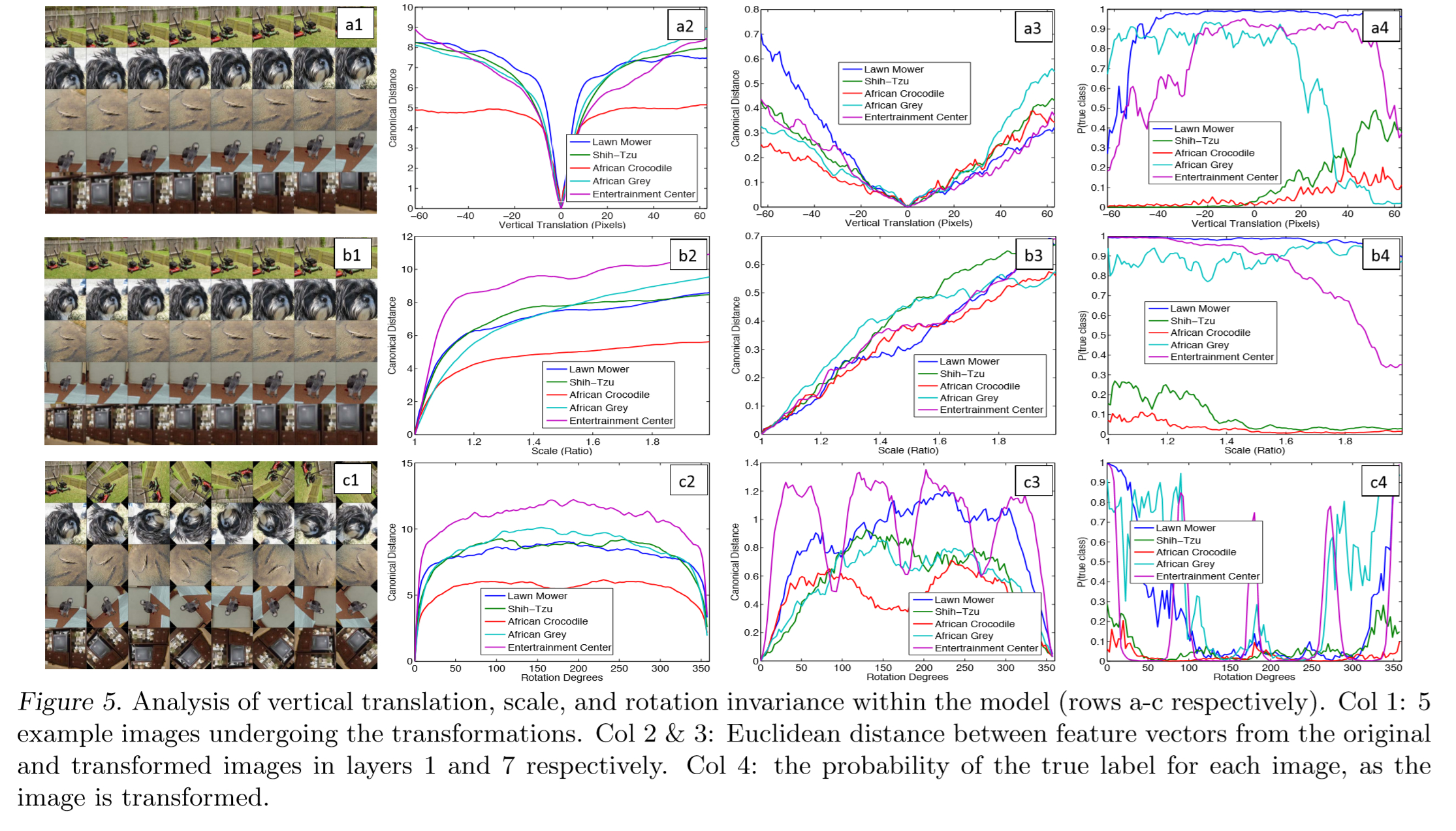
还有一种方法在 Visualizing and Understanding Convolutional Networks 这篇论文中提到过就是通过通过平移,转换,遮挡等操作来分析网络,但是我们可以用一张图片的这些变化和它自己进行对比来形成三元组。分析题目的相同激活点的特征。
现在的方面都是在网络训练结束后才来对比,但是我们可以从一开始就从那几个方面来定义一个差距方程,计算完后来看这两种图片计算后的差距是多大,可以是阈值也可以是具体值。
4.总结
- yolo 算法看起来挺简单的,但是很多细节也需要看源码去分析。
- train中的调参也是要加强的,最近总是有很多nan训练不出来的。
- 可解释的理解也还需要构建。