操作系统Pintos 实验一 Thread 全解
内容简介
操作系统课程的必修内容是实现斯坦福大学开发的pintos操作系统。通过对pintos的开发与运行,实现对操作系统各个部分的理解与深入。
本实验一律采用Ubuntu 16.04 Server版作为运行环境。
本教程旨在记录使用pintos实验一的全过程,涉及到安装、调试、开发等等方面,将持续进行更新,希望大家多多支持。
组员
- 刘 欢 16281044 计科1601
- 孙汉武 16281047 安全1601
- 杨涵晨 16281052 计科1601
- 王晗炜 16281049 计科1601
- 邢飞龙 16281050 计科1601
- 谭天云 16281048 计科1601
Pintos的安装与简介
安装准备:git,bochs,git和bochs的详细安装教程请自行google。
sudo apt-get install git提醒bochs使用
make命令前,请使用./configure --enable-gdb-stub --with-nogui命令安装命令行版的bochs工具。
pintos的源代码下载安装:
-
pintos源码下载:
git clone http://cs140.stanford.edu/pintos.git
-
当前目录将出现
pintos文件夹
-
源码下载完毕后,目录结构(
pintos/src)如下图所示
文件夹功能说明:
- threads:为基核准备的源代码,在实验一中我们会进行修改。
- userprog:为装载用户程序的源代码,在实验二我们会进行修改。
- vm:基本上空的目录,在实验三我们实现虚拟内存。
- filesys:基本文件系统的源代码,从实验二开始使用,实验四开始修改。
- devices:键盘、定时器、硬盘等等IO设备的接口源代码,在实验一中我们会修改定时器。其他情况我们不会进行修改。
- lib:标准C库的子集实现。这个目录中的代码被编译到内核中,并且从实验二开始,用户程序也会在其下运行。在内核代码和用户程序中,我们可以使用
#include<...>的方式引用这个目录中的header文件。我们基本上不用修改本目录中的源代码。- lib/kernal:这个目录中的代码仅被内核使用。还包含在内核代码中可以自由使用的一些数据类型的实现:位图、双向链表和哈希表。在内核代码中,我们可以使用
#include<...>的方式引用这个目录中的header文件。- lib/user:这个目录中的代码仅被用户程序使用。在用户程序中,我们可以使用
#include<...>的方式引用这个目录中的header文件。- test:每个项目的测试。如果它可以帮助您测试提交用例,可以自行修改。
- examples:从实验二开始使用的示例用户程序。
- misc & utils:如果尝试在自己的计算机上运行Pintos才会用到这些文件。请在当前用户目录下的
.zshrc或.bashrc文件中添加utils文件夹的环境变量。
-
编译Pintos,进入到threads目录,使用
make命令
此时目录中将会出现一个
build文件夹,里面包含了Makefile和一些子目录,随后在其中构建内核。在此我们分析一下build文件夹中的内容。
build文件夹内容分析:
- Makefile:pintos/src/Makefile.build的复制。它描述了如何构建内核。
- kernel.o:整个内核的对象文件。这是将各个单独内核源文件编译目标文件链接到单个目标文件的结果。
- kernel.bin:内核的内存映像,即加载到内存中运行Pintos内核的二进制文件。是被剥离调试信息的kernel.o,这节省了大量空间,使得内核不会被内核加载器512KB容量所限制。
- loader.bin:内核加载器的内存映像,使用汇编语言编写的小块代码,用于将内核从磁盘读出内存并启动它。它刚好是512字节长度,大小被PC BIOS所固定。
- 构建的文件夹中同样包含子文件夹,子文件夹中的内容由
.o与.d文件组成,分别对应编译器生成的目标文件与依赖项文件。依赖项告诉make在更改其他源文件或头文件时,需要重新编译哪些源文件。
-
运行pintos,使用命令
pintos -v -- run alarm-multiple测试pintos样例参数详解:
-v 关闭VGA显示
-- 参数引导头
run 调用运行命令
alarm-multiple 内置测试样例


中途无报错即为安装成功。最后使用
Control + c退出程序。特别提醒,安装过程中非常容易出现各种各样的库缺失的报错现象,请大家按照报错提示,自行google处理。我遇到的问题是一个叫做
warning: can't find squish-pty, so terminal input will fail的问题。解决方案是在pintos/src/utils目录中执行make命令后,使用sudo ln squish-pty /usr/local/bin/解决。在安装成功pintos系统并通过基本的测试用例后,我们可以开始正式的实验了,接下来我将通过分模块的方式,依次记录各个实验的详细的步骤。如果你在安装过程中遇到了问题,并无法通过google解决,欢迎在文章下方留言,我会尽快回复。
Mission 1 ALARM CLOCK
实验说明
重新实现timer_sleep(),在devices / timer.c中定义。虽然当前代码提供了一个工作实现,但是它的实现方式我们称为“忙等待”,即它在循环中检查当前时间是否已经过去ticks个时钟,并循环调用thread_yield()直到循环结束。重新实现它以避免繁忙的等待。
暂停执行调用timer_sleep()的线程,暂停ticks个时钟。除非系统处于空闲状态,线程不需要在ticks个刻度之后唤醒,而将它放在就绪队列中。 timer_sleep()对于实时操作的线程很有用,例如每秒闪烁一次光标。timer_sleep()的参数以计时器刻度表示,而不是以毫秒或任何其他单位表示。每秒有TIMER_FREQ计时器刻度,其中TIMER_FREQ是在devices / timer.h中定义的宏。默认值为100,不建议更改此值,因为任何更改都可能导致许多测试失败。
在timer.c中,还存在timer_msleep()、timer_usleep()、timer_nsleep()函数,用于实现睡眠特定的毫秒、微秒和纳秒,但是它们会在必要时候调用timer_sleep()我们无需修改它们。
实验过程
首先阅读源代码的timer_sleep()函数的实现原理:
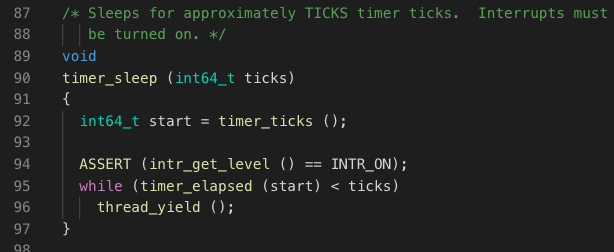
当前执行进程调用timer_sleep(ticks)时,函数通过判断循环条件当前时间是否已经大于或等于了ticks个计数器刻度,如果条件不满足,则会调用thread_yield()函数,将当前进程直接加入到就绪队列,并调用进程切换的相关函数将CPU让给在就绪队列中的进程(如果就绪队列中有的话)。
可以发现,调用timer_sleep()的进程,在CPU就绪队列及CPU运行队列间来回切换,即尽管没有到ticks个计数器刻度,但CPU仍会通过激活改进程,以通过循环的方式来判断是否进程还需要再次执行thread_yield(),这个过程中,浪费了进程反复切换之间需要的CPU时间。
深入思考这个问题产生的原因,是尽管进程阻塞要求时间未到,但在该进程未被重新调度完成前,操作系统本身不知道到底进程被阻塞了多少计数器刻度。而解决这个问题的合理方式,我们也自然可以想到,在操作系统中描述进程的是struct thread,只要我们在这个进程PCB中记录了当前阻塞的时间和总共要被阻塞的时间或还要被阻塞多长时间,我们就可以在不切换进程前确认进程是否应该被加入就绪队列。
修改后的timer_sleep()函数如下:
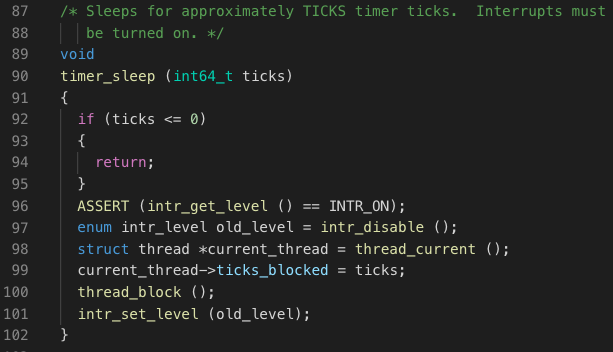
我们在函数中,将要sleep的时间ticks传入到进程PCB中的ticks_blocked用于记录当前PCB指示的进程还需要阻塞多长时间。通过thread_block()函数,设置进程的阻塞状态,并调用进程切换。
既然引入了ticks_block这个变量,我们需要在结构体struct thread中加入对其的声明,并在进程创建函数thread_creade()加入对ticks_block赋初值0的操作。随后我们要做的就是在每个时钟中断时检查,哪些进程使block状态并且休眠时间还有剩余。值得注意的是,这里必须要求同时满足两个条件,因为操作系统中存在进程因为等待锁而阻塞的状态,这些进程并非因为主动调用timer_sleep()函数而阻塞。
所以接下来的工作就变成了,在系统时钟中断处理函数中加入进程检查函数,对因为timer_sleep()而阻塞的进程,执行阻塞时间自减或加入CPU就绪队列操作。首先寻找CPU时钟中断处理函数,在timer.c文件中:
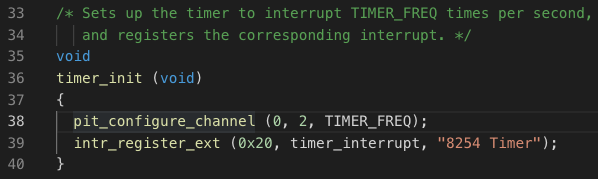
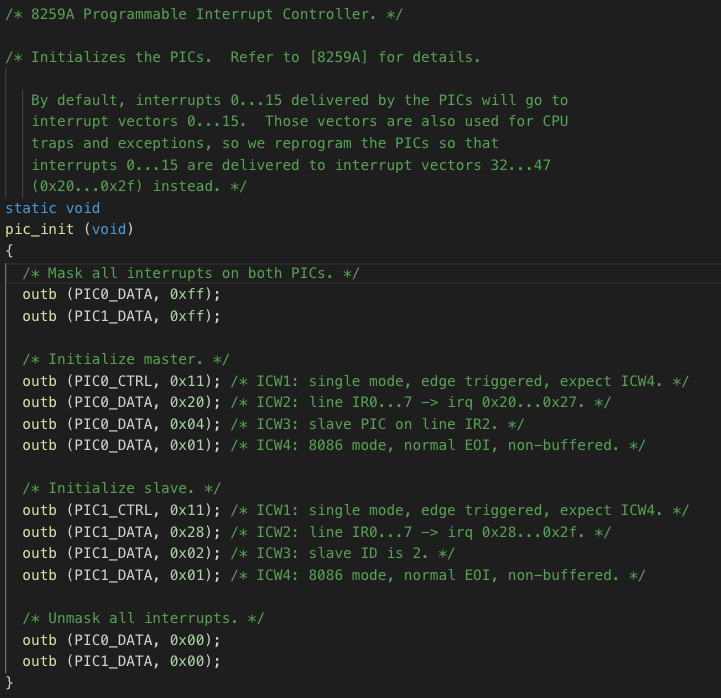
首先,通过pit_configure_channel (0, 2, TIMER_FREQ)函数,向8254定时器设置了每秒执行TIMER_FREQ计时器刻度次的周期定时,使用的通道是0通道,计数方式是mode2即周期性脉冲。根据硬件编程,实现了计数器0向8259A芯片0号管脚发送中断请求的操作。由于CPU将0-15号中断向量占用,所以通过pic_init()函数,将中断0-15传送到32-47,具体的代码及注释如下。它在Boot引导完毕前执行完毕。
随后,通过 intr_register_ext (0x20, timer_interrupt, "8254 Timer")函数,我们向32中断向量注册了timer_interrupt()函数,这个函数就是每秒执行TIMER_FREQ次的时钟中断处理函数。即我们需要在这个函数中实现我们之前设计的逻辑。原函数如下图所示:
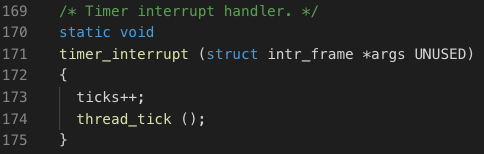
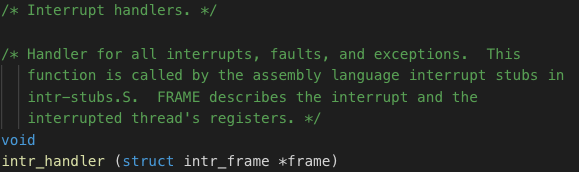
实现的功能一是CPU时钟计数自加。二是用户进程时间片用完后,当出现外部中断时,中断服务程序处理完毕后,阻塞进程执行(调用thread_yield()函数)。详细代码在interrupt.c的intr_handler()函数中。
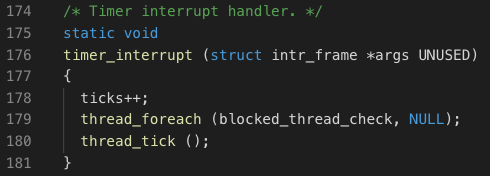
我们在时钟中断处理函数中,加入一行即可,实现对每个进程都调用blocked_thread_check函数:
最后再实现blocked_thread_check函数,实现具体对传入进程的上述逻辑功能。
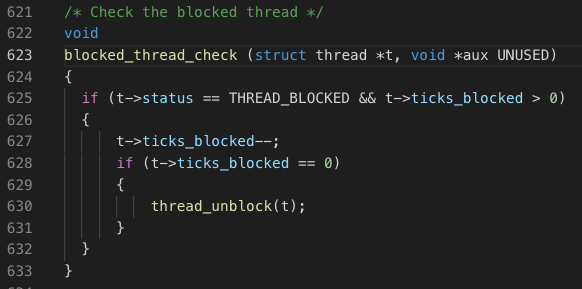
当当前待检进程为阻塞状态并且阻塞时间剩余大于0个计时器刻度时执行,剩余刻度自减。若减为0,调用thread_unblock函数将当前进程加入到就绪队列。
实验结果
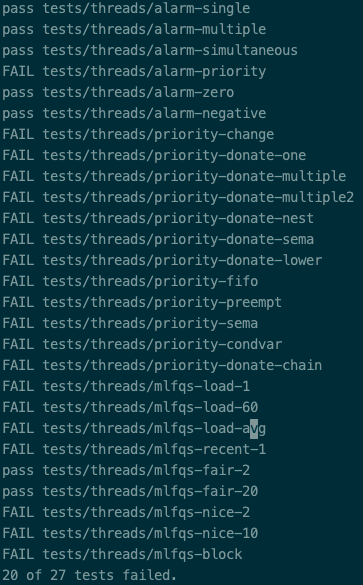
我们到/src/thread目录下执行make check,可以进行测试。
至此,MISSION_1 ALARM CLOCK编写完毕,执行测试有如下结果:
Mission 2 PRIORITY SCHEDULING
实验说明及过程
本实验主要涉及的是进程的优先级调度问题,这里我们先找到线程结构的定义struct thread:

我们可以看到这里已经定义了线程优先级的数据成员:priority,这是进行优先级调度的基础,那么我们现在可以思考如何实现这一机制。
pintos中给出的调度函数schedule()中使用了next_thread_to_run()函数获取下一个需要调度执行的进程,当就绪队列中还存在进程则返回队列的首元素,而这个队列是怎么维护的呢?我们通过查找thread.c源程序中的与ready_list相关的函数我们可以发现有以下三个函数来向队列中添加成员:
init_thread()thread_unblock()thread_yield()
它们都调用了函数list_push_back来增加队列中的成员,在list.c中我们可以找到此函数的具体实现:直接在队列的队尾插入。

如此一番调研之后我们就完全搞清楚了pintos的原始调度机制:先来先服务。这与我们所需要的优先级调度还存在较大差别,而在此基础上我们其实不难想出改进的方法:原始的线程结构体中已经给出了整数类型的优先级大小成员,我们只要能够通过比较各个线程的优先级大小维护一个优先级从大到小的优先级队列就能完成此种调度。
至此我们又有了两种思路:
- 每次调度之前对就绪队列根据优先级大小进行一次排序
- 每次插入成员之时按照优先级大小进行插入
很容易看出这两种方式都能达到目的,但后一种方式的效率要远远高于第一种方式。因此我们便开始着手实现第二种方式,而当我们继续浏览list.c文件时可以发现其中已经存在list_sort和list_insert_ordered函数,其功能分别为将列表排序和按序插入列表,我们在此自然选择使用其后一个插入函数,根据其传入的参数可知我们只需要重新实现一个比较函数(list_less_func *less)就可调用此函数完成优先级队列的维护。

下面给出优先级比较函数,根据传入的成员优先级大小返回一个布尔值。

至此我们初步完成了优先级队列的维护,这也是实现优先级调度的第一步。
继续阅读pintos官方文档种的优先级调度要求,我们可以看见如下一段话:
Implement priority scheduling in Pintos. When a thread is added to the ready list that has a higher priority than the currently running thread, the current thread should immediately yield the processor to the new thread. Similarly, when threads are waiting for a lock, semaphore, or condition variable, the highest priority waiting thread should be awakened first. A thread may raise or lower its own priority at any time, but lowering its priority such that it no longer has the highest priority must cause it to immediately yield the CPU.
这段话中提到当就绪队列中存在一个优先级比当前线程优先级更高的线程时,系统要立刻进行调度,先执行优先级较高的线程,当优先级较高的线程存在的时候,优先级较低的线程一定会放弃CPU。
根据此要求结合我们阅读过的thread.c中的源代码,我们可以发现系统当前并不会对优先级大小的变化做到即时敏感:当有新的线程创建或者已有的线程优先级发生改变时系统并不会马上进行分析并调度,其中当创建新线程时它只会维护就绪队列,而队列中或当前线程优先级发生变化之时并不会有其它操作随之产生。
针对这一问题我们其实很快就能想出解决的方案:当任何与线程优先级改变相关的操作发生时,进行一个判断分析,若操作之后产生的新优先级高于当前线程的优先级,调用thread_yield函数进行线程调度并维护优先级队列,实现线程的抢占式调度。
根据此思路我们从源码中找出与优先级变化相关的函数,经过查找分析我们可以看到只有以下两个函数符合条件:


其中init_thread是初始化线程的函数,这属于我们分析的第一种情况:有新的线程产生,此时因为在函数的最后已经有对就绪队列维护的操作,因此我们只需判断其优先级大小是否高于当前线程,若高于则用thread_yield函数使当前线程放弃CPU。(因为函数在初始化时的状态为阻塞,需要在thread_create中调用unblock函数将其置于Ready状态,在这之后我们才能对其进行调度,因此此调度模块补充在thread_create函数中)
而thread_set_priority函数的作用使改变当前线程的优先级,而当优先级发生改变时影响就绪队列的情况十分常见,此时我们只需直接调用thread_yield函数便可完成对就绪队列的维护和线程的优先级调度。
下面给出修改之后这两个函数的代码:


完成了抢占式调度的涉及,我们接着分析pintos官方文档中的mission 2的任务指示,主要在2.2.3节中。
分析之后它主要提出了三个问题,我们先来看看这几个问题
When threads are waiting for a lock, semaphore, or condition variable, the highest priority waiting thread should be awakened first. A thread may raise or lower its own priority at any time, but lowering its priority such that it no longer has the highest priority must cause it to immediately yield the CPU.
总结来说就是,在有锁或者信号量的时候,我们如何安排进程优先级?
在目前的pintos中 ,锁的申请机制较为简单,只涉及信号量的PV操作并设置锁的拥有线程,这里先给出lock_acquire的源码:

对于其他申请该锁的线程,并未在相关线程中记录,只是在信号量中维持了一个等待队列。

我们可以进一步探究这个队列的维护机制,查找与成员waiters相关的函数,我们可以发现只在信号量的PV操作中会对其进行操作,实现的机制和就绪队列一致:先来先服务。这无疑也不符合优先级调度的要求,我们需要在之后的实验中进行改进。
我们接着阅读官方给出的实验指导书:
One issue with priority scheduling is “priority inversion”. Consider high, medium, and low priority threads H, M, and L, respectively. If H needs to wait for L (for instance, for a lock held by L), and M is on the ready list, then H will never get the CPU because the low priority thread will not get any CPU time. A partial fix for this problem is for H to “donate” its priority to L while L is holding the lock, then recall the donation once L releases (and thus H acquires) the lock.
这里涉及到的问题就是线程优先级的捐赠,我们通过以下案例分析对其进行说明:
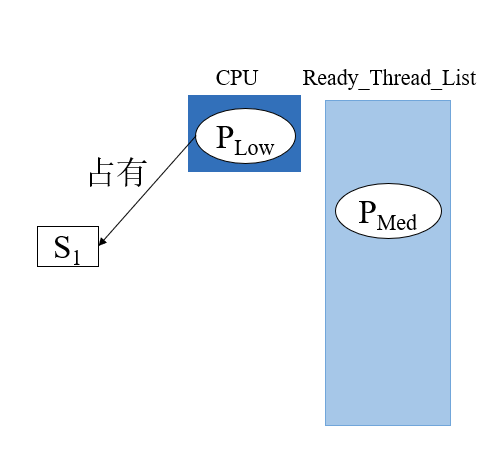
- 刚开始有一个进程P_low 占用了CPU,并且申请了一个lock锁。这时有一个 P_med 进程进入了就绪队列,优先级比较高的进程, 根据
thread_yield (),P_low会让出cpu给P_med
-
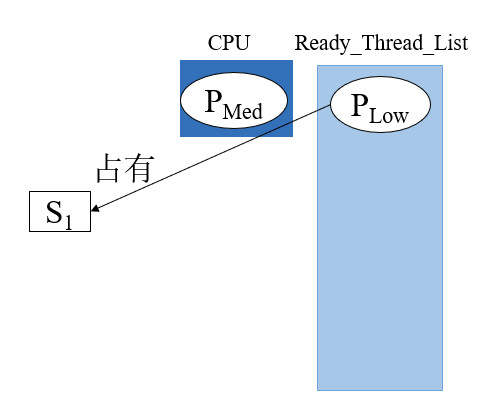
P_med 占用cpu,P_low放入等待队列ready_list,其还保存着对应的lock占用
-
此时P_high就绪,根据优先级调度其开始对CPU占用,P_med和P_low按序回到就绪队列中

-
那么,现在就会造成死锁。死锁存在于
P_low->S_1->P_high之间。
至此我们可以得出结论:直接按照优先级调度的方式切换线程可能会造成死锁,结合就绪队列的调度机制会继续导致优先级处于二者之间的所有线程也被锁住。
死锁无疑造成操作系统的崩溃,因此必须给出一个解决的方案来破解。略经思考我们发现最高效的解决方案就是先运行其中一个线程,但这个操作也不能违背线程调度的优先级和锁机制。根据以上要求我们开始引入优先级捐赠机制。

根据实验指导书,优先级捐赠的机制如下:当发现高优先级的任务因为低优先级任务占用资源而阻塞时,就将低优先级任务的优先级提升到等待它所占有的资源的最高优先级任务的优先级。而当被捐赠线程释放该锁之后其优先级需要恢复至原始的优先级。
继续阅读余下的指导书。
You will need to account for all different situations in which priority donation is required. Be sure to handle multiple donations, in which multiple priorities are donated to a single thread. You must also handle nested donation: if H is waiting on a lock that M holds and M is waiting on a lock that L holds, then both M and L should be boosted to H’s priority.
这简短的一段话又给我们抛出了两个在优先级捐赠中会出现的问题:
- 如何实现多个线程对单个线程的优先级捐赠
- 如何实现多个线程之间的递归优先级捐赠
第一点的情况较为容易理解,我们在这里使用一个简单的案例介绍递归捐赠:
P_Low正在占用锁Lock1,P_Med正在占用锁Lock2,P_Med正在申请Lock1,此时便会进行优先级的捐赠,P_Low的优先级变为Med,此时P_High开始申请Lock2,P_Med的优先级则会变为High,通过递归捐赠,P_Low的优先级也会变为High。

以上两点其实并不属于当前调度过程中存在的问题,需要我们在实现优先级捐赠时注意。
经过上面的问题分析,和对应的源代码分析,我们对这个任务余下的待实现需求做一个总结:
- 优先级队列
- 维持一个ready_list 优先级排队队列
- 将condition的waiters队列实现为优先级队列。
- 将信号量的等待队列实现为优先级队列。
- 单锁实现
- 当发现高优先级的任务因为低优先级任务占用资源而阻塞时,就将低优先级任务的优先级提升到等待它所占有的资源的最高优先级任务的优先级。
- 释放锁的时候若优先级改变则可以发生抢占。
- 多锁实现
- 如果一个线程被多个线程捐赠, 维持当前优先级为捐赠优先级中的最大值(acquire和release之时)
- lock 锁被释放的时候, 高进程应该收回优先级捐赠,并且停止unblock状态。
- 在对一个线程进行优先级设置的时候, 如果这个线程处于被捐赠状态, 则对base_priority进行设置, 然后如果设置的优先级大于当前优先级, 则改变当前优先级, 否则在捐赠状态取消的时候恢复base_priority。
- 在释放锁对一个锁优先级有改变的时候应考虑其余被捐赠优先级和当前优先级。
- 捐赠时间
- 线程处于ready_list中等待时
- 线程处于sleep状态,也就是block状态时,也可以改变优先级

基于以上需求,我们开始对pintos中的源码进行修改。
在上文的分析中我们就可以得知:若存在优先级的捐赠则必然会存在释放锁后被被捐赠线程的优先级恢复,因此单单在thread结构体中使用一个成员priority是无法完成的,我们需要一个额外的成员来储存线程在被捐赠之前的优先级,也就是base_priority。经过以上的实验我们也可发现原始thread结构体中并未设计与锁相关的成员变量(原l始的锁和信号量队列与优先级无关,和就绪队列一样属于先来先服务,不需要在结构体中添加这些),因此我们还需要在线程的结构体中添加两个成员变量:locks和lock_waiting,分别代表线程已经拥有的锁和正在申请的锁,前者为一个队列,后者只需设置为锁类型(lock)的变量,下面给修改后的thread结构体:

既然线程结构体中缺乏与锁相关的成员,自然锁结构体中也缺乏与线程相关的成员,我们找到lock的源码可以发现其中只存在两个成员:holder和semaphore,即拥有者和信号量,这对于实现优先级调度和优先级捐赠来说肯定是不够的,我们需要继续增加两个成员变量:elem和max_priority。这两个成员代表的意义也很好理解:前者是当前线程在信号量队列中位置(在原始的队列中,当前线程一定位于队列的首部),后者则是表示该锁的信号量队列中线程的最高优先级(用于优先级的捐赠),下面也给出修改过后的lock结构体代码:

有了这些修改过后的结构体我们就可以开始实现与锁相关的优先级调度程序。
因为前面涉及到了结构体的修改,那么我们势必要对其初始化函数进行修改,所以我们先对lock_init和init_thread进行修改,完成以上几项的初始化:


接下来我们不妨分析以下涉及锁的线程调度过程,根据之前阅读的代码,可以用以下流程图来梳理我们需要实现的过程:

根据流程图,我们首先着眼于lock_acquire函数,在锁的申请时我们首先考虑的就是锁是否已经被线程占用,若锁未被占用则直接将此线程占用该锁,对信号量进行P操作,而当该锁存在线程占用时,我们就需要将该锁的最大优先级和此线程的优先级进行比较,若此线程的优先级高则要进行优先级的捐赠,随后在被插入信号量的等待队列中。
所以我们这里需要先实现一个优先级捐赠函数thread_donate_priority,它的功能其实只有两个:
- 改变线程当前的优先级
- 若该线程处于就绪队列中需要对就绪队列重排
第一个任务很容易使我们想到之前实现抢占式调度时修改过的thread_set_priority函数,但仔细分析后我们可以发现此函数的逻辑并不适用与此:当前线程的优先级大小不仅和其本身的优先级相关,还与捐赠线程的优先级大小相关,之前修改的函数的本意其实是修改当前运行线程(这就意味着线程的状态一定为RUNNING,因此修改过后我们可以根据调整的优先级大小直接判断其是否调用thread_yield)的base_priority而非priority,且在原来的设置中,并不能指定任意线程进行修改。因此我们需要再次编写一个函数对任意线程的当前优先级进行更新,不过再次之前我们无疑要再次对thread_set_priority函数进行修改,设置base_priority并判断是是否满足重新调度的条件(没有锁约束或当前优先级发生改变),下面给出修改后的代码:

之后我们定义一个thread_update_priority函数来更新线程的当前优先级(我们目前只认为线程的当前优先级只会在捐赠优先级的条件下发生改变),此函数的功能也较为简单:将线程的base_priority和其所有锁的最大优先级进行比较,将当前优先级设置为其中的最大值。如此实现的优先级捐赠适用于多个线程对单个线程的优先级捐赠,而这里我们唯一的难点就是如何获取其所有锁的最大优先级的最大值,但稍加分析我们也能依照之前的方法简单实现:将locks(线程的锁队列)维护成一个优先级有序队列再取出第一个成员的优先级即可,维护的方法和就绪队列稍有不同,使用了前文提到的list_sort方式(此队列优先级改变的情况较为复杂,用插入的方式容易出现问题),下面一并给出排序函数和优先级更新函数的代码:

拥有锁的线程不一定是当前正在占用CPU的线程,因此我们还需考虑一种情况:此线程正处于优先队列之中,完成了更新之后我们必须重新对就绪队列进行维护。至此我们的捐赠函数的逻辑就完全设计完成 了,下面给出其完整代码:

至此我们退回lock_acquire函数,这里我们还需注意的是优先级的捐赠是一个递归的问题,我们需要将其关联的每一层锁的拥有线程调整为不比此线程低的优先级,这里我们会用一个while结构加以实现。解决了优先级捐赠的问题,我们可以开始进行信号量的P操作,这也不用太多赘述,我们只需再原有基础上将信号量的队列也维护成优先级有序队列,实现方式和就绪队列一致。

获取锁的最后一步就是将此线程变为锁的拥有者,但这一过程也并能沿用当前的方式,因为这会涉及到锁的最大优先级的改变:当一个线程拥有一个锁时,其优先级一定为此锁的最大优先级(包括优先级捐赠的情况)。接着我们还需要把该锁插入至线程的锁队列中,并修改锁的holder成员为当前线程。基于以上逻辑编写了函数thread_hold_the_lock。至此lock_acquire的编写随之完成,以下为两个函数的源码:


这里我们完成了获取锁的全部逻辑,接着只要补全释放锁的逻辑即可。相较于lock_acquire,lock_release的逻辑显得更简单一些,这里我们只需做三件事:
- 将对应锁从线程的锁队列中清除(线程脱离锁)
- 将锁设置为不被任何线程占用(锁脱离线程)
- 进行信号量的V操作
这三步都较为简单,第一步这里编写了一个``thread_remove_lock`函数来实现,主要功能也很容易想到:将该所从其锁队列中移除,更新线程的优先级(若处于被捐赠的状态,还回此锁捐赠的优先级),实现代码如下:

第二步就更为简单,只需将lock的holder成员设置为NULL即可。
对于第三步,我们则要对原始的sema_up函数进行修改,其与sema_down函数的唯一不同点在于在对信号量序列中的最高优先级线程进行了unblock操作并改变信号量值之后需要马上使用thread_yield函数来保证抢占式调度。下面给出sema_up和lock_release函数的源代码:


以上就完成了mission2的全部代码编写,下面可以开始对其进行测试:
实验结果
我们到/src/thread目录下执行make check,可以进行测试。
至此,MISSION_2 PRIOTITY SCHEDULING编写完毕,执行测试有如下结果:

Mission 3 ADVANCED SCHEDULER
实验说明
实现类似于BSD调度程序的多级反馈队列调度程序,以减少在系统上运行作业的平均响应时间。
与优先级调度调度程序一样,高级调度程序同样基于进程的优先级来调度进程。但是高级调度程序不会执行优先级捐赠。必须编写必要的代码,以允许在Pintos启动时选择调度算法策略。 默认情况下,优先级调度程序必须处于活动状态,但必须能够使用-mlfqs内核选项选择4.4BSD调度程序。 在main()函数中parse_options()解析选项时,传递此选项会将threads / thread.h中声明的thread_mlfqs设置为true。
启用4.4BSD调度程序后,线程不再直接控制自己的优先级。 应忽略thread_create()的优先级参数,以及对thread_set_priority()的任何调用,并且thread_get_priority()应返回调度程序设置的线程的当前优先级。 高级调度程序不会在以后的任何项目中使用。
非常重要:可以在附录B中找到关于BSD调度程序的详细说明,这是我们编程的唯一指导基础。
实验指导
通用调度程序的目标是平衡线程的不同调度需求。 执行大量I / O的线程需要快速响应时间以保持输入和输出设备忙,但需要很少的CPU时间。 另一方面,绑定计算的线程需要花费大量CPU时间来完成其工作,但不需要快速响应时间。 其他线程介于两者之间,I / O周期被计算周期打断,因此需求随时间变化。 精心设计的调度程序通常可以同时满足具有所有这些要求的线程。
对于项目1,必须实现附录B中描述的调度程序。 调度程序类似于[McKusick]中描述的调度程序,它是多级反馈队列调度程序的一个示例。 这种类型的调度程序维护几个可立即运行的线程队列,其中每个队列包含具有不同优先级的线程。 在任何给定时间,调度程序从最高优先级的非空队列中选择一个线程。 如果最高优先级队列包含多个线程,则它们以“循环”顺序运行。
调度程序的多个方面需要在一定数量的计时器滴答之后更新数据。 在每种情况下,这些更新应该在任何普通内核线程有机会运行之前发生,这样内核线程就不可能看到新增的timer_ticks()值而是旧的调度程序数据值。 4.4BSD调度程序不包括优先捐赠。
Niceness
线程优先级由调度程序使用下面给出的公式动态确定。 但是,每个线程还有一个整数nice值,用于确定线程对其他线程的“好”程度。 nice值为0不会影响线程优先级。 nice值从1至20,会降低线程的优先级,并导致它放弃一些原本会收到的CPU时间。 另一种情况,nice值从-20到-1,往往会从其他线程中抢占CPU时间。
初始线程nice值为0。 其他线程初始值从其父线程继承nice值。 必须实现下面描述的功能,供测试程序使用。 在threads / thread.c中为它们提供了框架定义。
1
2
3
4
5
// 返回当前进程的nice值
int thread_get_nice (void);
// 设置当前进程的nice值为new_nice,并重新计算进程的优先级,若正在运行的进程不再是最高优先级,则阻塞
void thread_set_nice (int new_nice);
计算 Priority
我们的调度程序有64个优先级,因此有64个就绪队列,编号为0(PRI_MIN)到63(PRI_MAX)。 较低的数字对应较低的优先级。因此优先级0是最低优先级,优先级63是最高优先级。 线程优先级最初在线程初始化时计算。 对于每个线程,每四个时钟周期也会重新计算一次。 在任何一种情况下,都由公式确定
\(priority=PRI\_MAX-(recent\_cpu/4)-(nice*2)\)
recent_cpu是线程最近使用的CPU时间的估计值(见下文),而且公式中的nice值为当前进程的nice值。 结果应向下舍入到最接近的整数(截断)。 recent_cpu和nice的系数1/4和2,分别被发现在实践中很好地工作但缺乏更深的含义。 计算得到的优先级始终为位于PRI_MIN到PRI_MAX的有效范围内。
此公式为线程重新计算优先级提供了依据。 这是防止饥饿的关键:最近没有收到任何CPU时间的线程的recent_cpu值为0,除非有一个很高的nice值,否则它会很快就会收到CPU运行时间。
计算 recent_cpu
我们希望recent_cpu可以表征每个进程“最近”收到多少CPU运行时间。此外,作为一种改进,最新收到的CPU时间应该比其之前的CPU时间权重更大。 一种方法是使用n个元素的数组来跟踪在最后n秒的每一个中接收的CPU时间。 然而,这种方法每线程需要O(n)空间,并且每次计算新加权平均值需要O(n)时间。
相反,我们使用指数加权移动平均线,它采用这种一般形式:
\(x(0)=f(0),\\x(t)=ax(t-1)+(1-a)f(t),\\a=k/(k+1)\)
其中x(t)是整数时间t≥0的移动平均值,f(t)是被平均的函数,k > 0控制衰减速率。我们可以通过以下几个步骤迭代公式:
\(x(1)=f(1),\\x(2)=af(1)+f(2),\\.\\.\\.\\x(5)=a^4f(1)+a^3f(2)+a^2f(3)+af(2)+f(5)\)
f(t)的值在时间 t 的权重为1,在时间 t + 1 的权重为 a,在时间 t + 2 的权重为 2,等等。我们还可以将x(t)与 k 相关联:f(t)在时间 t + k 具有大约 1 / e 的权重,在时间 t + 2k 具有大约1 / e2 等等。从相反方向,f(t)在时间 t + loga w 衰减到 f(t)*w。
在创建的第一个线程中,recent_cpu的初始值为0,或者在其他新线程中为其父进程值。 每次发生定时器中断时,除非空闲线程正在运行,否则recent_cpu仅对正在运行的线程递增1。 此外,每秒一次,使用以下公式为每个线程(无论是运行,准备还是阻塞)重新计算recent_cpu的值:
\(recent\_cpu=(2*load\_avg)/(2*load\_avg+1)*recent\_cpu+nice,\)
其中load avg是准备运行的线程数的移动平均值(见下文)。 如果load avg为 1 ,表示单个线程正在竞争CPU,那么recent_cpu的当前值在log2 / 3 0.1 ≈ 6秒内衰减到原值的 0.1。 如果load_avg为2,则衰减到原值的 0.1需要 log3 / 4 0.1 ≈ 8秒。 结果是recent_cpu估计了线程“最近”收到的CPU时间量,衰减率与竞争CPU的线程数成反比。
某些测试所做的假设要求在系统计数器每达到一秒完全重新计算recent_cpu,即条件timer_ticks () % TIMER_FREQ == 0成立。
对于具有负nice值的线程,recent_cpu的值可能为负。 不要将负的recent_cpu设置为0。
需要考虑此公式中的计算顺序。先计算recent_cpu的系数,然后再做乘法,否则可能会产生溢出。
必须实现在threads/thread.c中的thread_get_recent_cpu()函数。
1
2
// 返回当前线程recent_cpu值的100倍,四舍五入到最接近的整数
int thread_get_recent_cpu (void);
计算 load_avg
最后,load_avg(通常称为系统负载平均值)估计在过去一分钟内,在准备队列中的平均线程数。 像recent_cpu一样,它也是指数加权移动平均。 与priority和recent_cpu不同,load_avg是系统范围的,而不是特定于线程的。 在系统启动时,它被初始化为0。此后每秒一次,根据以下公式更新:
\(load\_avg=(59/60)*load\_avg+(1/60)*ready\_threads,\)
ready_thread是在更新时运行或准s备运行的线程数(不包括空闲线程)。
有些测试假设当计时器达到1秒倍数时,即当timer_ticks()%TIMER_FREQ == 0时,必须要重新更新load_avg,而不是在其它时间。必须实现位于threads/thread.c中的函数:
1
2
// 返回当前系统 load_avg 的100倍,四舍五入到最接近的整数
int thread_get_load_avg(void);
总结
以下公式总结了实现高级调度程序所需的计算。 它们不是调度程序要求的完整描述。
每个线程在-20和20之间具有nice值。 每个线程也有一个优先级,介于0(PRI_MIN)到63(PRI_MAX)之间,每四个滴答使用以下公式重新计算:
\(priority=PRI\_MAX-(recent\_cpu/4)-(nice*2).\)
recent_cpu测量一个线程“最近”收到的CPU时间量。在每个CPU时钟中,正在运行的线程的recent_cpu增加1。每秒一次,每个线程的rencent_cpu以这种方式更新:
\(recent\_cpu=(2*load\_avg)/(2*load\_avg+1)*recent\_cpu+nice.\)
load_avg估计在过去一分钟内准备运行的平均线程数。 它在启动时初始化为0,并按每秒重新计算一次,如下所示:
\(load\_avg=(59/60)*load\_avg+(1/60)*ready\_threads.\)
ready_threads是在更新时运行或准备运行的线程数(不包括空闲线程)。
定点小数及其计算
在上面的公式中,priority、nice和ready_thread是整数,但是recent_cpu和load_avg是实数。 但是,Pintos不支持内核中的浮点运算,因为它会使内核变得复杂和变慢。 出于同样的原因,真正的内核通常具有相同的限制。 这意味着必须使用整数模拟实数的计算。 本节介绍基础知识。
其基本思想是将整数的最右边的几位视为表示分数。例如,我们可以将带符号的32位整数的最低14位指定为小数位,这样整数x代表实数 x/214 。这个叫做 17.14 定点数,最大能够表示 (231-1)/214 ,近似 131071.999 。
假设我们使用 p.q 的定点数格式,并且设 f=2q 。根据上面的定义,我们可以通过乘以 f 将整数或实数转换为 p.q 格式。例如,基于17.14 格式的定点数转换 59/60 ,(59/60)214 = 16110。将定点数转换为整数则除以 f 。
C中的“/”运算符向零舍入,也就是说,它将正数向下舍入,向负数向上舍入。要舍入到最近,将 f / 2 先与正数相加再除,或者先在负数中减去 f / 2 再除。
下表总结了如何在C中实现定点算术运算。在表中,x和y是定点数,n是整数,定点数是带符号的p.q格式,其中p + q = 31,和f是1 « q:

实验过程
根据实验说明,我们可以知道bool变量thread_mlfqs指示是否启用高级调度程序,并且高级调度程序不应包含优先级捐赠的内容,所以,在Mission_2中实现的优先级捐赠代码,需要使用if判断以保证在使用高级调度程序时,不启用优先级捐赠。随后,我们可以根据实验指导中的详细说明一步步完成本次实验。
首先,根据上述给定点数的计算方法,编写定点数的计算方法,实现 16.15 格式定点数计算方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/* Basic definitions of fixed point. */
typedef int fixed_t;
/* 16 LSB used for fractional part. */
#define FP_SHIFT_AMOUNT 16
/* Convert a value to fixed-point value. */
#define FP_CONST(A) ((fixed_t)(A << FP_SHIFT_AMOUNT))
/* Add two fixed-point value. */
#define FP_ADD(A,B) (A + B)
/* Add a fixed-point value A and an int value B. */
#define FP_ADD_MIX(A,B) (A + (B << FP_SHIFT_AMOUNT))
/* Substract two fixed-point value. */
#define FP_SUB(A,B) (A - B)
/* Substract an int value B from a fixed-point value A */
#define FP_SUB_MIX(A,B) (A - (B << FP_SHIFT_AMOUNT))
/* Multiply a fixed-point value A by an int value B. */
#define FP_MULT_MIX(A,B) (A * B)
/* Divide a fixed-point value A by an int value B. */
#define FP_DIV_MIX(A,B) (A / B)
/* Multiply two fixed-point value. */
#define FP_MULT(A,B) ((fixed_t)(((int64_t) A) * B >> FP_SHIFT_AMOUNT))
/* Divide two fixed-point value. */
#define FP_DIV(A,B) ((fixed_t)((((int64_t) A) << FP_SHIFT_AMOUNT) / B))
/* Get integer part of a fixed-point value. */
#define FP_INT_PART(A) (A >> FP_SHIFT_AMOUNT)
/* Get rounded integer of a fixed-point value. */
#define FP_ROUND(A) (A >= 0 ? ((A + (1 << (FP_SHIFT_AMOUNT - 1))) >> FP_SHIFT_AMOUNT) \
: ((A - (1 << (FP_SHIFT_AMOUNT - 1))) >> FP_SHIFT_AMOUNT))
由于本实验涉及到的公式均与时钟中断有关,所以,我们将上述的公式迭代计算的相关代码,写入我们在Mission_1中详细介绍过的timer_interrupt()时钟中断处理函数中。其原函数为:

之前已经接介绍过,本实验在thread_mlfqs变量为true的情况下进行。所以,我们需要通过if对此条件进行判断,以免影响其他实验的正常运行。
包括,每个时钟中断都更新的recent_cpu、每一秒更新的load_avg、每四个时钟更新一次的priority,如下图所示。接下来,我们分别介绍这些函数。

首先是thread_mlfqs_increase_recent_cpu_by_one(void),若当前进程不是空闲进程则当前进程加1,注意定点数加法。

接下来是thread_mlfqs_update_load_avg_and_recent_cpu(void)函数,首先根据就绪队列的大小计算load_avg的值,随后根据load_avg的值,更新所有进程的recent_cpu值及priority值。

最后,通过thread_mlfqs_update_priority (struct thread *t)函数,更新当前进程的priority值,注意,一定要保证每个线程的优先级介于0(PRI_MIN)到63(PRI_MAX)之间。

最后到了收尾工作,我们要在struct thread结构体中加入nice和recent_cpu这两个变量,其完整的定义如下:

并在init_thread()线程初始化时,将nice与recent_cpu置零。注意recent_cpu是定点数0。我们需要在thread.c中定义全局变量load_avg,注意是定点数类型。在thread_start()函数中初始化为0。
根据上述指导内容,在thread.c中将需要我们实现的函数全部写入。

实验结果
我们到/src/thread目录下执行make check,可以进行测试。
至此,MISSION_3 ADVANCED SCHEDULER编写完毕,执行测试有如下结果:

致谢
撰写本文的目的在于记录小组pintos实验一过程,
在此特别感谢以上作者。