【论文笔记 7】CAM 论文重读
没有服务器就是没有生产力啊!
最近思想有点偏,我觉得很有必要回来看看CAM,说不定有啥收获
1.CAM 证明
以前没看懂的。
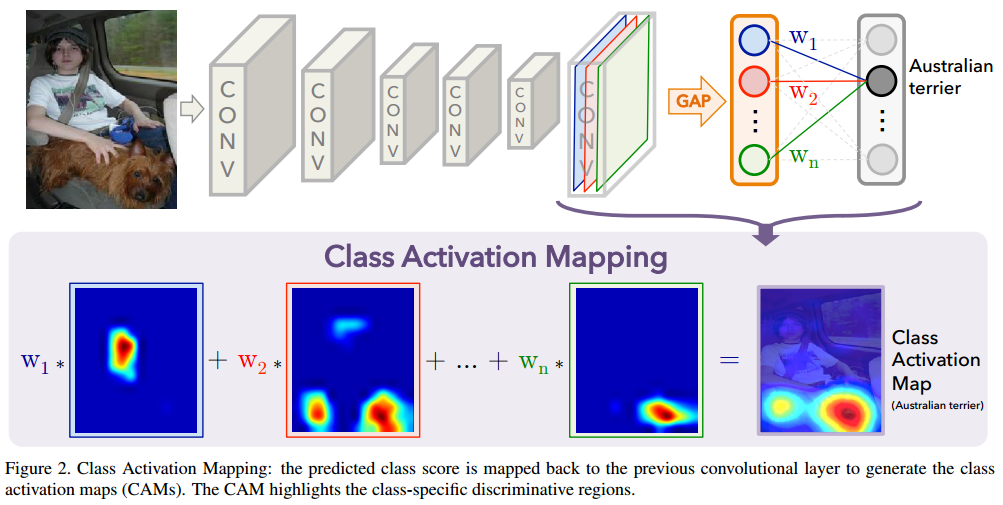
举个例子来说:在mnist分类问题中,原来topconv 是一个(64 * 10 * 10)经过GAP 之后变换为 (64*1) 。
所有它对每个类就会有64个W,W总共有10 * 64.

然后它通过数学证明了,Mc(x,y)是针对每个类每个topconv上的层(10*10)的重要性。
然后它简单的对每个topconv层进行了叠加。
2.思路
这几周,我在做的就是在GAP后进行度量,得到对应类的类中心。
有类中心,也就是可以得到对应本样本跟每个类中心之间的距离,也就是说对每一个类我们都要对应的指标。
怎么把这个系数加上去就是问题核心所在?
我们现在其实是在, 最后面对一些重要的点,进行乘系数。
可以对每个层的重要信息进行乘系数。

我发现它的一个问题就是如果判断错标签的时候,就用错误类的系数进行cam。
那我们如果现在gap分类的时候,然后可以逆转这种情况,也就可以挽救。
而且我们现在兵分两路。
一部分想让这个系数影响前面cam的形成,另一部分想提升准确率。
如果我们得到是 k1,k2, ……,kc 个系数,跟每个类中心的距离。然后把这个kc个值直接乘到Sc上面。
那这个一定会影响前面w1,w2…Wn 这些参数,来影响cam,而且影响分类的结果。
3. GAP 上面加SVM
CNN的更高层(比如AlexNet的fc6,fc7)已经被证明能提取到很有效的通用特征(generic features),其在各种个图片数据集上都有极好的性能。这里,我们证明了我们的GAP CNN学到的特征可以很好地作为通用特征,识别出用于分类的区别性区域,尽管没有针对这些特定任务进行训练。为了得到与softmax层相似的权重,我们在GAP的输出上简单训练了一个SVM。 首先,对比我们的方法与一些基准模型在下面场景及物体分类任务中的表现:表5对比了我们最好的网络GoogLeNet-GAP提取的特征与AlexNet的fc7提取的特征和GoogLeNet的ave pool提的特征比较。

4. CAM 也可以是一种数据增强,数据预处理方法?
对重要信息进行切割,成另外一副图片?
GAP 后,经过SVM都有很好的结果。
很多的做语义分割的就是基于cam来得到一个结果。
5. 改进实验模块
5.1. t-she查看类的分布
1
2
3
4
5
6
7
8
9
10
X_tsne = TSNE(n_components=2,learning_rate=100).fit_transform(GAP_data)
#X_pca = PCA().fit_transform(iris.data)
print("finishe!")
plt.figure(figsize=(12, 6))
#plt.subplot(121)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=GAP_label)
#plt.subplot(122)
#plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target)
plt.colorbar()
plt.show()

5.2. 错误实例查看
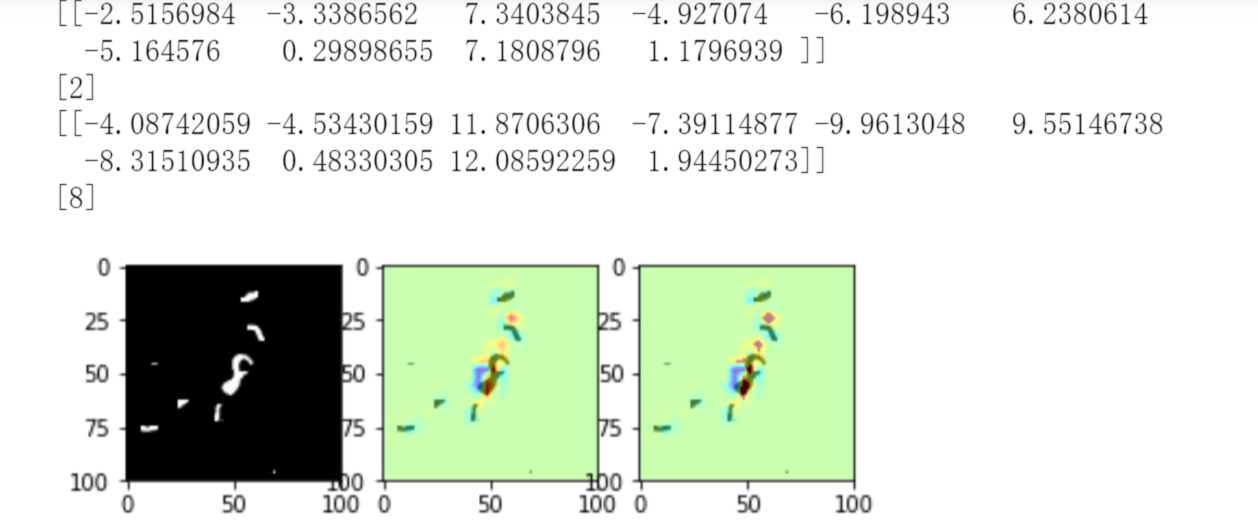
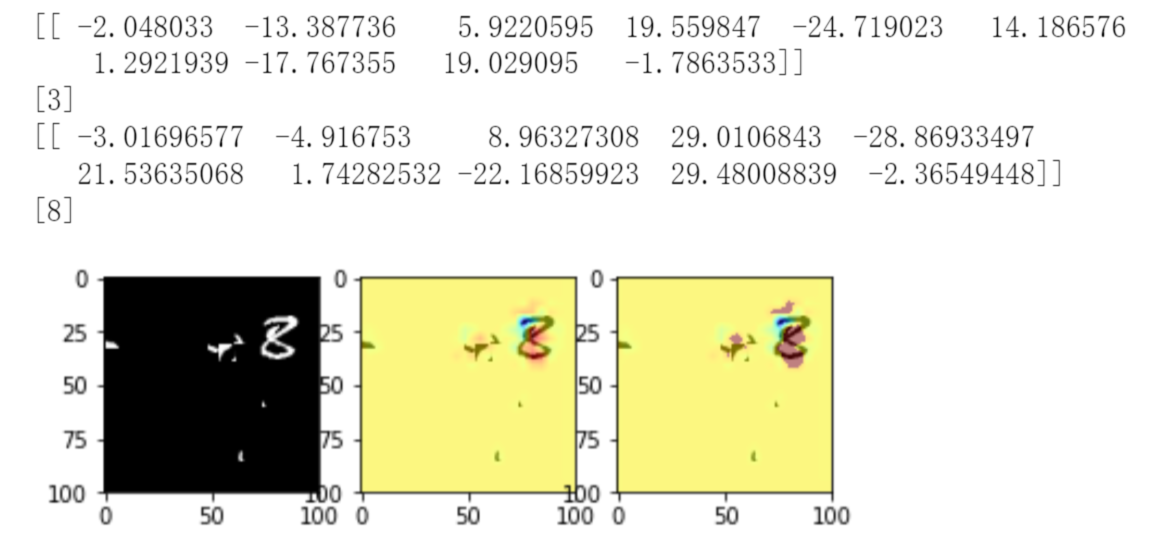

5.3. 在每层上面加权
future work
最近要备考大学期间的最后一门考试了
所以分请主次的话,这个就先放一放
但是我最近的思路需要记录一下
就是我利用k-means 实际上是将多个本来就有关系的向量结合起来了,但是我觉得这样还是有点简单
所以看看能不能设计一种更好的方式去实现这个思想
计算量不用考虑,但是效果要好
主要是看看grad-cam是用什么方法没有改变网络结构,、
还有就是network in network的方式可不可以提升这个性能