论文笔记8:Sanity Checks for Saliency Maps
前言
先说点生活的事情,最近健身真的好累啊!!但是也身体力行发现了一个道理
生活就像健身,不坚持到最后一组,前面所有都等于白练
每天起床都是肌肉撕裂的感觉,知识也是这样吧,撕破然后重塑
正文
1. Short overview
这是一篇相对理解性的论文,主要提出在多种Sanity Method被提出的情况下,到底那种是好的解释方法
这种方法正好可以在我自己的CAM改善模型上,进行测试,利用这种方法来从Sanity map 角度验证改进的效果
2. 衡量标准
再说衡量标准之前,我先阐述一下我们为什么要做 可解释性
- 针对一个模型,具有好的解释性,意味着可以更好的被人理解
- 改进模型时,解释性可以帮助我们进行改善模型,进行debug
我个人认为 可解释性其实很大一部分就是 再找相关性 不管是梯度,反卷积 都是再求一个 invariant
这个相关性 到底跟我们的模型 在哪里有关系 是在参数上,结构上还是类标等其他因素?
因此 在这篇文章中 虽然他没有 提出衡量标准 这个话题
但是我自己的总结就是:
- sanity method 是否跟训练好参数关系很大?
- 如果有很大关系,那么这个方法就不是好的方法 我们是需要利用map去改善的 而map跟参数的关系很大就说明 map对改善参数 进行debug 没有很大帮助
- 如果没有很大关系,就可以利用这个map来看 在一定参数或结构下 通过map更好 来进行调参
- sanity method 是否跟data的标注有很大关系?
- 如果一个方法依赖于数据的标记,没有标注和有随机标注 训练后 他们会有很大差别 也就说模型 很大程度只关注于 图片和模型的关系 而不是数据本身
- 对置换标签的不敏感性揭示了该方法并不依赖于实例和原始数据中存在的标签之间的关系。
3. 方法
根据上面的总结 提出了两种方法:
- 利用 随机网络中的参数 进行比较
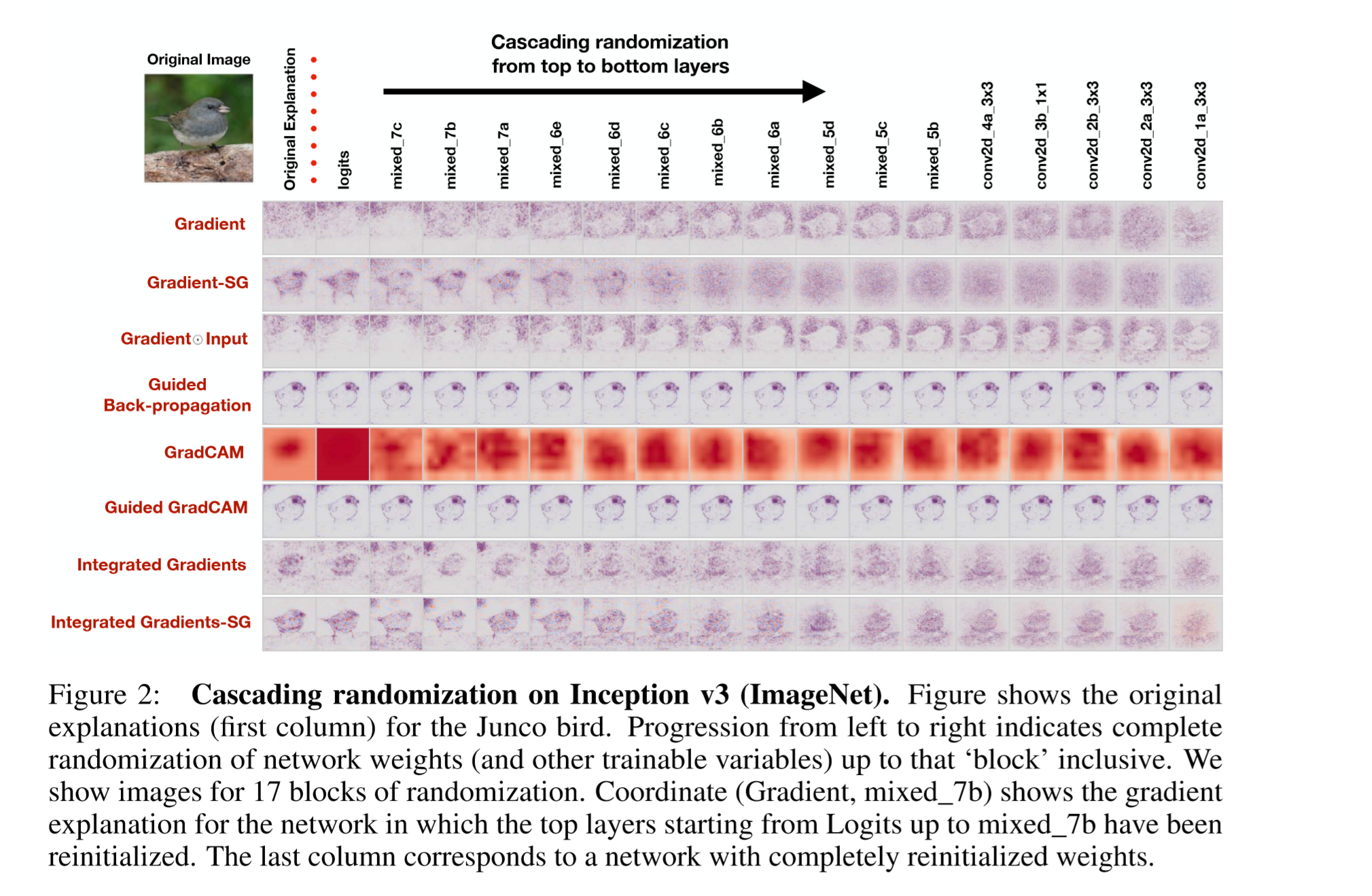
- 利用 随机数据标签 进行比较

4.实验发现
Guided BackProp and Guided GradCAM show no change regardless of model degradation.
5.个人实验总结
这个文章 对我最大的启发就是 去如果看待解释性的好坏
我自己在改进别人的网络,好坏的衡量标准的确是一个问题 以前总是使用 准确率来衡量
现在就可以从这两方面入手再看看
6. future work
什么future 明天就干活
- 重新写一套tensorflow代码,在cifar上实现的
- 网络可以选取 inception v3
- 然后先利用 cam 把结果 在 tensorboard上展示一遍
- 把自己的想法 封装起来
- 然后进行本实验方法的 实现 然后画图进行对比
加油💪