深度学习中预训练参数加载以及finetune等常见操作
1. cat vs dog 数据集实战
直接看图吧,这是在5000轮后的实现,tensorboard真的好用

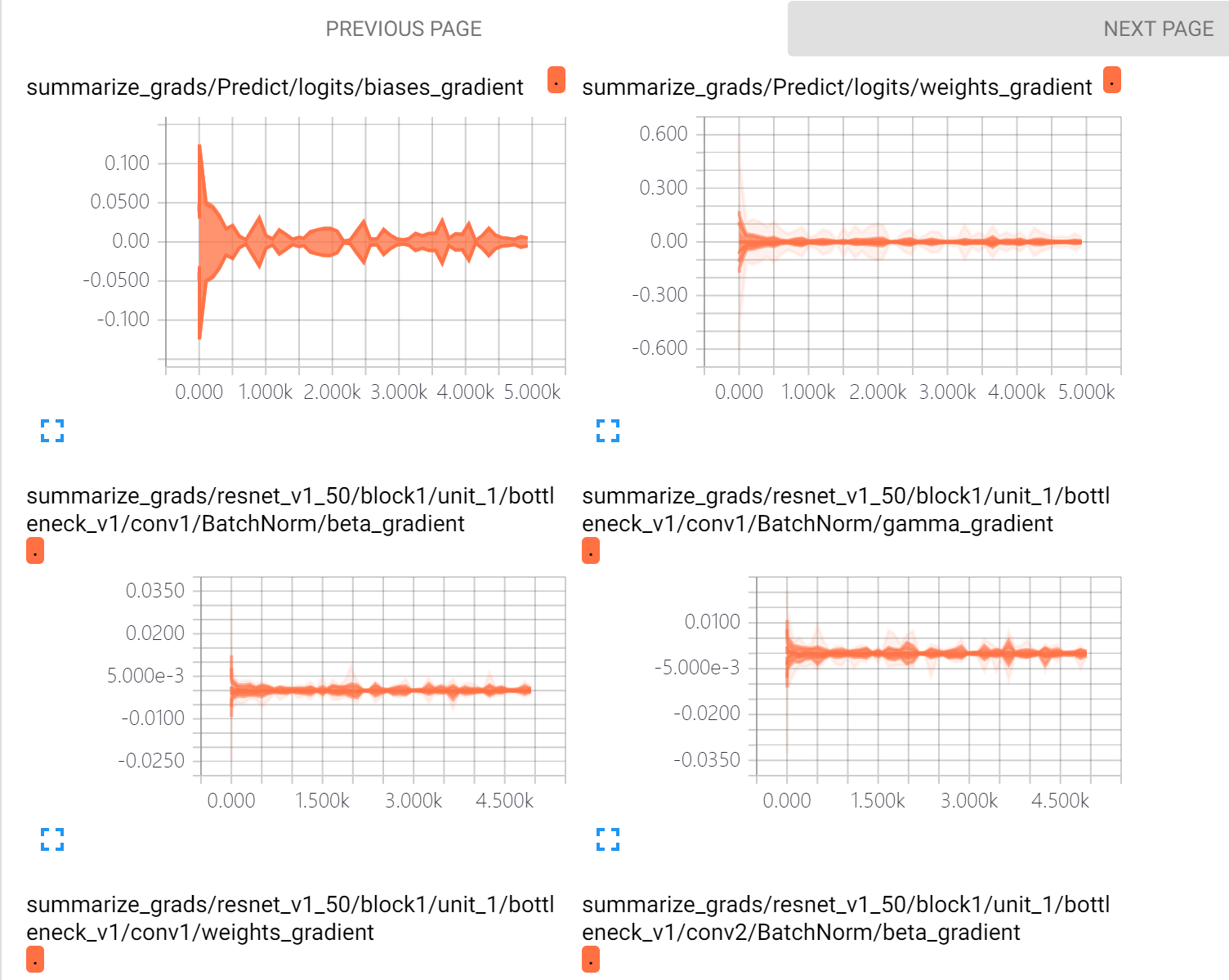
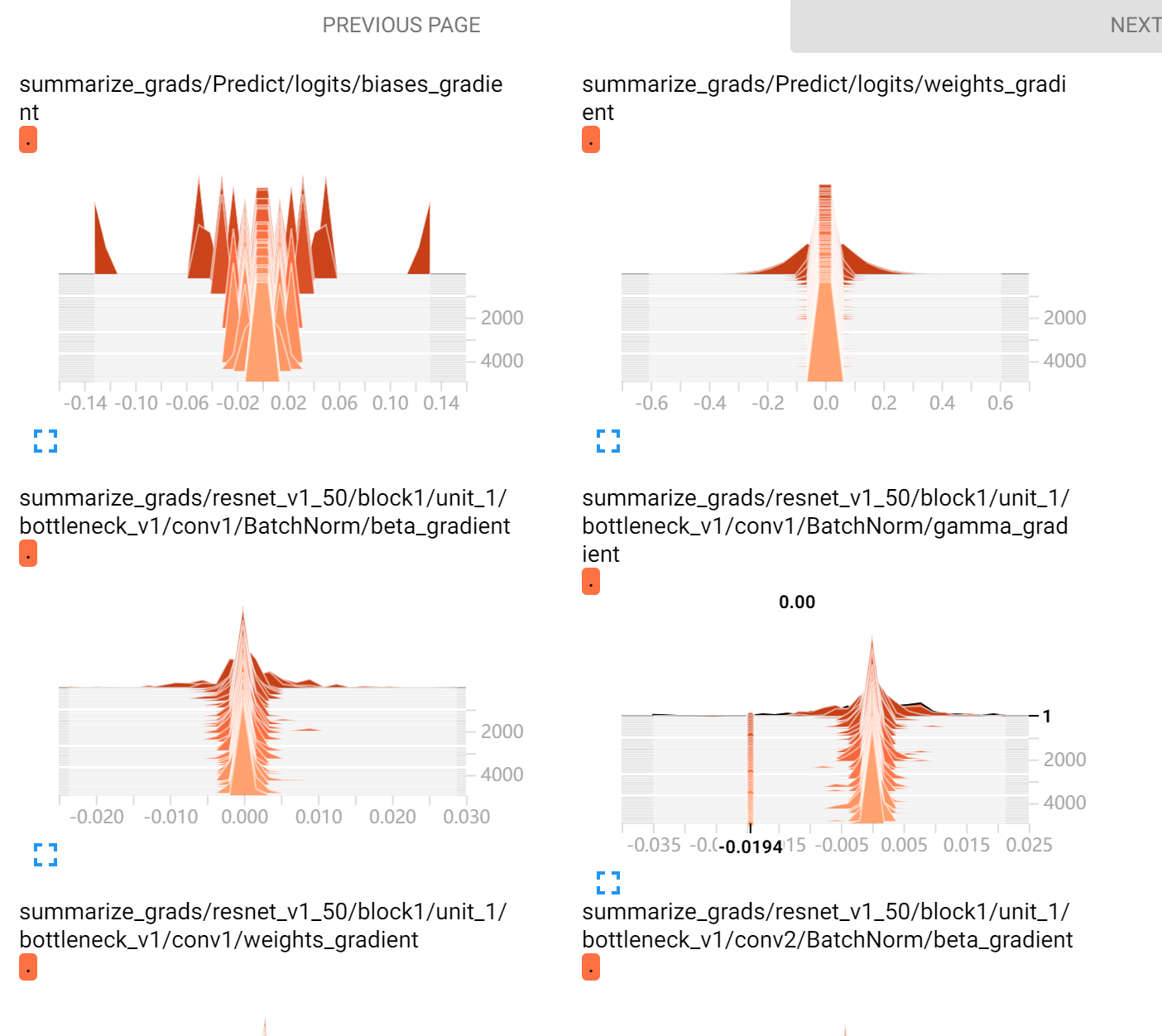
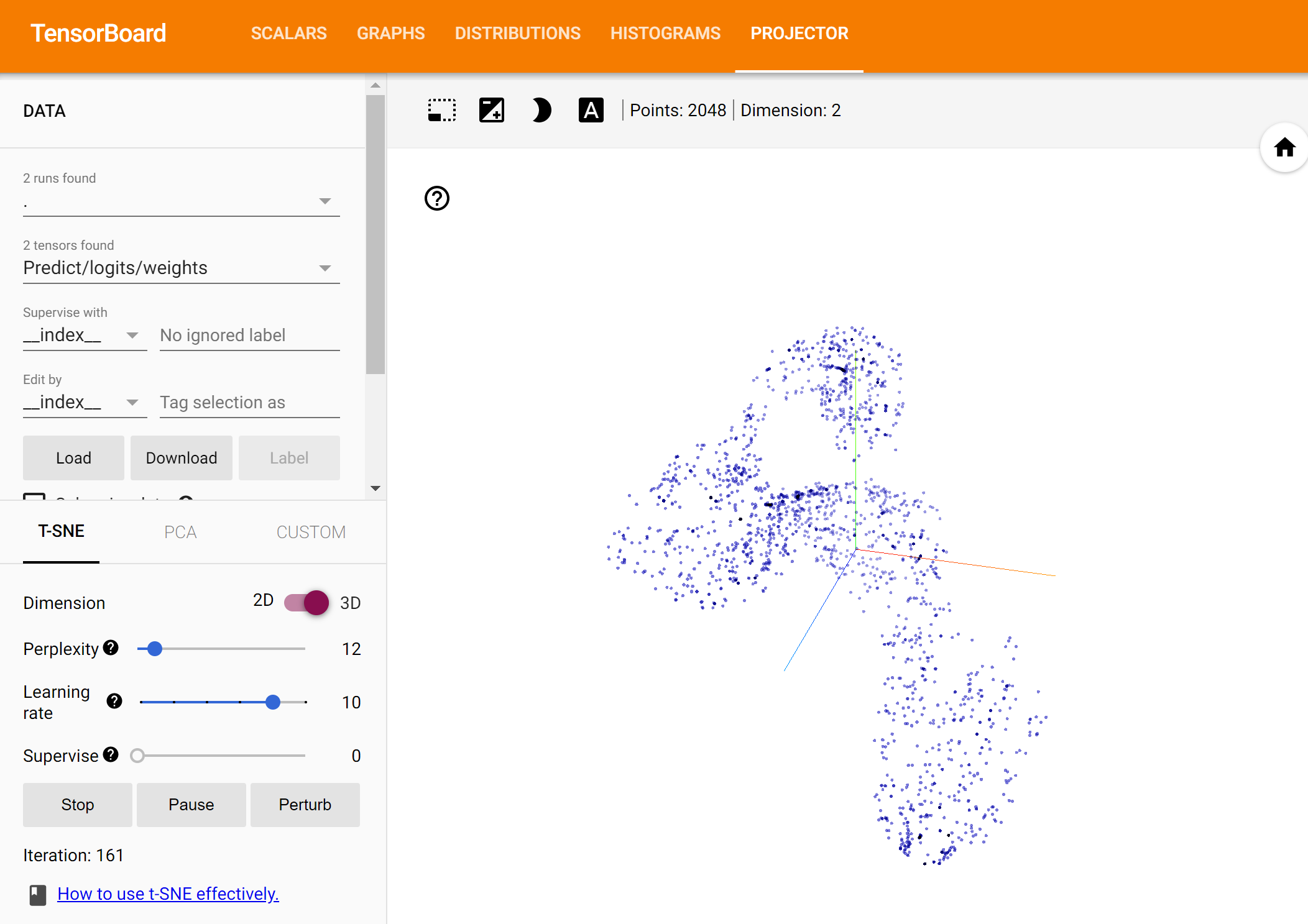
最后还有一个神奇的东西!!其实展现出来的并不太好,后续还得好好学习一下
2. finetune模型
在利用典型的网络模型时,我目前使用的主要用法有三点
- 加载ckpt,然后重新定义网络的最后一层,即更换分类器,进行训练
- 只加载部分层,其他随机初始化
- 只训练部分层,其他freeze
- 取出某一层另作他用
这四点,在这段代码里都可以实现, 对应的函数也已经写清楚了!
这些都在train.py中存在
2.1 更换分类器
1
2
3
4
5
6
7
8
9
10
11
12
# resnet_v1_50 函数返回的形状为 [None, 1, 1, num]
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
#conv5 = endpoints['resnet/conv5']
# 为了输入到全连接层,需要用函数 tf.squeeze 去掉形状为 1 的第 1,2 个索引维度。
net = tf.squeeze(net, axis=[1, 2])
# 将resnet的最后一层输出进行处理,变成二分类
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None,
scope='Predict/logits')
2.2 加载部分层
1
2
3
4
5
#进行对应预训练模型的加载
if FLAGS.checkpoint_path:
# checkpoint_exclude_scopes = 'resnet_v1_50/conv1,resnet_v1_50/block1'
# 指定一些层不加载参数
init_variables_from_checkpoint()
2.3 freeze部分
1
2
3
4
5
6
# 冻结层设置,指定一些层不训练
# scopes_to_freeze = 'resnet_v1_50/block1,resnet_v1_50/block2/unit_1'
vars_to_train = get_trainable_variables()
train_op = slim.learning.create_train_op(loss, optimizer,
variables_to_train=vars_to_train,
summarize_gradients=True)
2.4 取出部分层
1
2
3
4
5
6
7
8
9
10
11
12
# resnet_v1_50 函数返回的形状为 [None, 1, 1, num]
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
conv5 = endpoints['resnet/conv5']
# 为了输入到全连接层,需要用函数 tf.squeeze 去掉形状为 1 的第 1,2 个索引维度。
net = tf.squeeze(net, axis=[1, 2])
# 将resnet的最后一层输出进行处理,变成二分类
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None,
scope='Predict/logits')