一.零样本学习(Zero-shot Learning)
1. Introduction
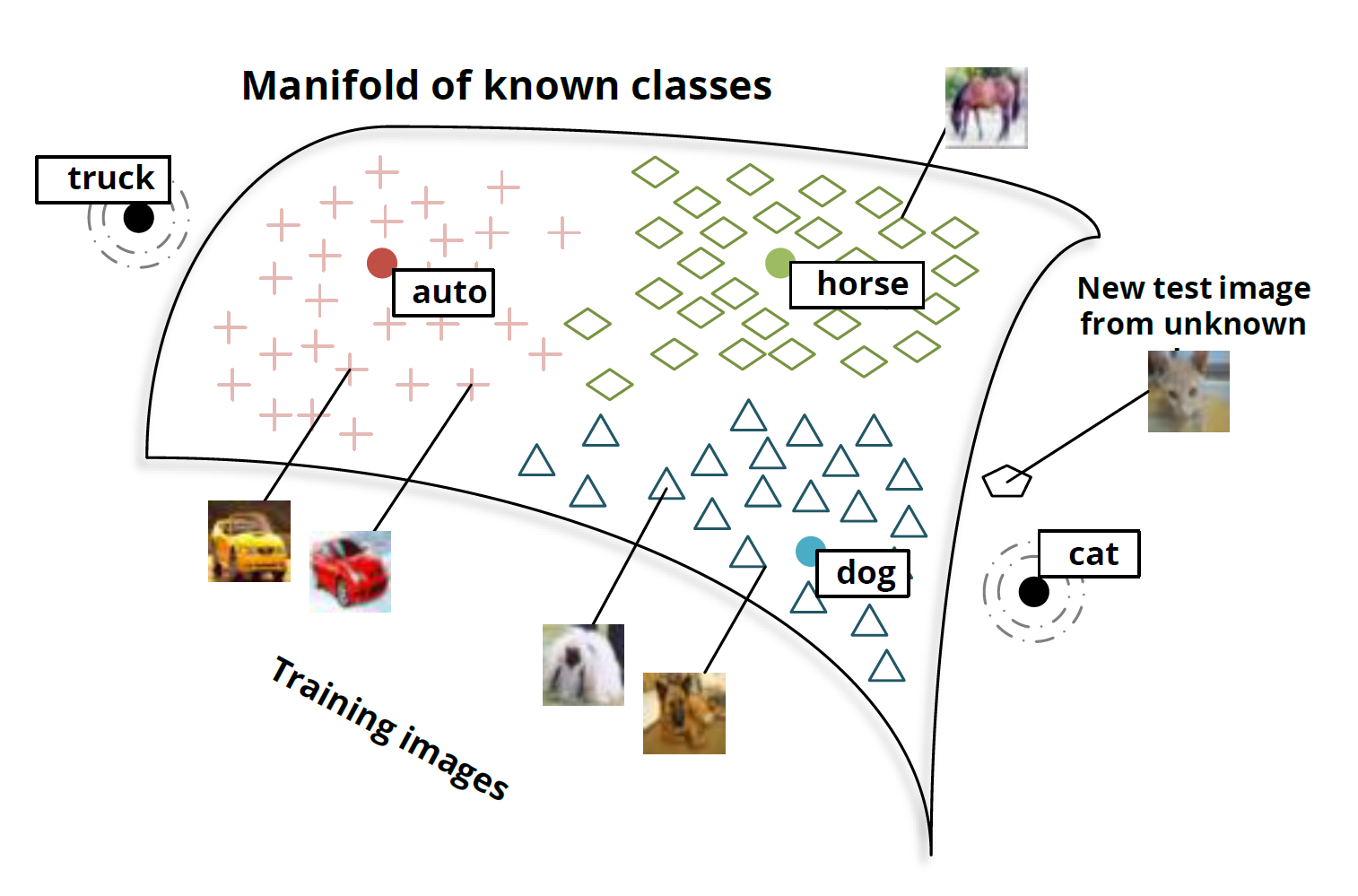
先说一个简单的例子:假设小暗(纯粹因为不想用小明)和爸爸,到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小暗安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小暗有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小暗根据爸爸的提示,在动物园里找到了斑马(意料之中的结局。。。)。
上述例子中包含了一个人类的推理过程,就是利用过去的知识(马,老虎,熊猫和斑马的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。(如图1所示)ZSL就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。

零样本学习:简单来说就是识别从未见过的数据类别,即训练的分类器不仅仅能够识别出训练集中已有的数据类别,还可以对于来自未见过的类别的数据进行区分。这是一个很有用的功能,使得计算机能够具有知识迁移的能力,并无需任何训练数据,很符合现实生活中海量类别的存在形式。
We study the problem of object classification when training and test classes are disjoint, i.e. no training examples of the target classes are available. This setup has hardly been studied in computer vision research, but it is the rule rather than the exception,because the world contains tens of thousands of different object classes and for only a very few of them image, collections have been formed and annotated with suitable class labels.
ZSL分两个阶段完成:
- 训练:捕获有关属性的知识
- 推理:然后使用知识对一组新类中的实例进行分类。
2.Methods
2.1 Using attribute-based Feature Spaces
根据Lampert C H, Nickisch H, Harmeling S. Learning to detect unseen object classes by between-class attribute transfer在09年提出的,根据人类可感知的高维属性特征来表示图片,即使用颜色,材料等等属性来对图片进行表示。

它的核心思想为:虽然物体的类别不同,但是物体间存在相同的属性,提炼出每一类别对应的属性并利用若干个学习器学习。在测试时对测试数据的属性预测,再将预测出的属性组合,对应到类别,实现对测试数据的类别预测针对每一个属性都有一个分类器,学习到对应的特征,然后将其进行组合!
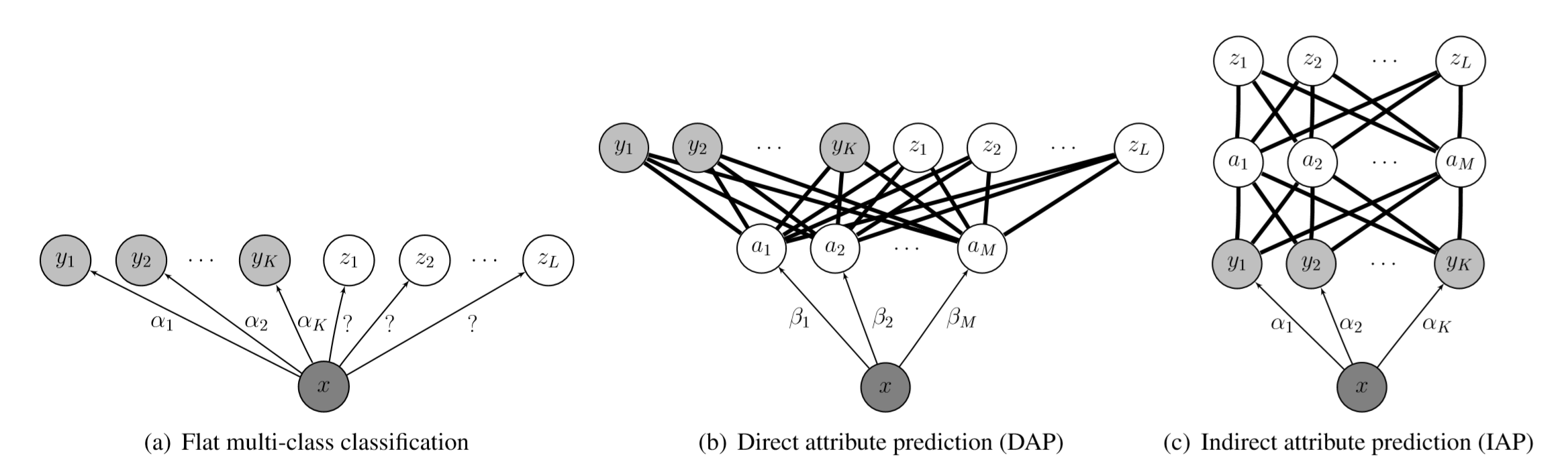
更近一步进行实现,也对特征进行细粒度的划分。
2.2 Word2vec
使用词向量来对样本进行表示,然后利用类之间的距离来计算其类标
通过其结果,我们可以看到其最大相似的类分别是哪些

2.3 Discriminative learning of latent feature
再说一个2018年的算法,相比于类间属性迁移方法,它主要增加了两个思路:
(1)设计了专门的网络(CNN等)找到图片中目标的主体部分
(2)出了利用人工标注的属性,还从原始图片中搜索潜在属性加入label embeding

二. 迁移学习(Transfer learning)
1.Introduction
迁移学习,顾名思义,就是要进行迁移。放到我们人工智能和机器学习的学科里讲,迁移学习是一种学习的思想和模式。 迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可以顺利地实现知识的迁移。
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
因此迁移学习提出了 Domain 域的概念,特别地,因为涉及到迁移,所以对应于两个基本的领域:源领域 (Source Domain) 和 目标领域 (Target Domain)。这两个概念很好理解。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移。
2. Methods
2.1 Deep Learning
这部分我自己用的比较多,所以先说, 在利用典型的网络模型时,主要用法有四点
- 加载ckpt,然后重新定义网络的最后一层,即更换分类器,进行训练
- 只加载部分层,其他随机初始化
- 只训练部分层,其他freeze
- 取出某一层另作他用
这四点,在这段代码里都可以实现, 对应的函数也已经写清楚了!主要用于tensorflow.slim.net
2.1.1 更换分类器
1
2
3
4
5
6
7
8
9
10
11
12
# resnet_v1_50 函数返回的形状为 [None, 1, 1, num]
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
#conv5 = endpoints['resnet/conv5']
# 为了输入到全连接层,需要用函数 tf.squeeze 去掉形状为 1 的第 1,2 个索引维度。
net = tf.squeeze(net, axis=[1, 2])
# 将resnet的最后一层输出进行处理,变成二分类
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None,
scope='Predict/logits')
2.1.2 加载部分层
1
2
3
4
5
#进行对应预训练模型的加载
if FLAGS.checkpoint_path:
# checkpoint_exclude_scopes = 'resnet_v1_50/conv1,resnet_v1_50/block1'
# 指定一些层不加载参数
init_variables_from_checkpoint()
2.1.3 freeze部分
1
2
3
4
5
6
# 冻结层设置,指定一些层不训练
# scopes_to_freeze = 'resnet_v1_50/block1,resnet_v1_50/block2/unit_1'
vars_to_train = get_trainable_variables()
train_op = slim.learning.create_train_op(loss, optimizer,
variables_to_train=vars_to_train,
summarize_gradients=True)
2.1.4 取出部分层
1
2
3
4
5
6
7
8
9
10
11
12
# resnet_v1_50 函数返回的形状为 [None, 1, 1, num]
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
conv5 = endpoints['resnet/conv5']
# 为了输入到全连接层,需要用函数 tf.squeeze 去掉形状为 1 的第 1,2 个索引维度。
net = tf.squeeze(net, axis=[1, 2])
# 将resnet的最后一层输出进行处理,变成二分类
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None,
scope='Predict/logits')

2.2 Distribution Adaptation
数据分布自适应 (Distribution Adaptation) 是一类最常用的迁移学习方法。这种方法 的基本思想是,由于源域和目标域的数据概率分布不同,那么最直接的方式就是通过一些变 换,将不同的数据分布的距离拉近。
2.2.1 边缘分布自适应方法 (Marginal Distribution Adaptation)
| 边缘分布自适应方法 (Marginal Distribution Adaptation) 的目标是减小源域和目标域 的边缘概率分布的距离,从而完成迁移学习。从形式上来说,边缘分布自适应方法是用$ P(xs)$ 和$ P(xt)$ 之间的距离来近似两个领域之间的差异。即:$$DISTANCE(Ds,Dt) ≈ | P(xs)−P(xt) | $$ |
2.2.2 条件分布自适应方法 (Conditional Distribution Adaptation)
| 条件分布自适应方法 (Conditional Distribution Adaptation) 的目标是减小源域和目标 域的条件概率分布的距离,从而完成迁移学习。从形式上来说,条件分布自适应方法是用$ P(ys | xs)$ 和$ P(yt | xt)$ 之间的距离来近似两个领域之间的差异。即: $$ DISTANCE(Ds,Dt) ≈ | P(ys | xs)−P(yt | xt) | $$ |
##### 2.2.3 联合分布自适应方法 (Joint Distribution Adaptation)
| 联合分布自适应方法 (Joint Distribution Adaptation) 的目标是减小源域和目标域的联 合概率分布的距离,从而完成迁移学习。从形式上来说,联合分布自适应方法是用 P(xs) 和 P(xt) 之间的距离、以及$ P(ys | xs) $和 $P(yt | xt) $之间的距离来近似两个领域之间的差异。即:$$ DISTANCE(Ds,Dt) ≈ | P(xs)−P(xt) | + | P(ys | xs)−P(yt | xt) | $$ |

小样本很难做,泛化能力不够很难,主要进行supervised learning 进行算力的精简。
cross domain word link。
simulation to real。
商业使用上面 主要是标签很花钱。
深度学习主要提取纹理。
机器学习是统计学习,都会有bias
关键问题 如何控制两个误差。
放缩找上界
三. 区别与联系
1. 区别
综上所述:
-
Zero-shot learning感觉更像是目标导向的,就是没数据!怎么学?可以迁移,也可以不迁移,用传统方法;例如上面讲到的斑马问题。
-
Transfer learning可以解决zero-shot learning面临的没数据的问题,也可以解决domain adaptation问题而且侧重于解决domain 源域与目标域直接的问题!
2. 联系
个人认为零样本学习算是迁移学习的一种吧,零样本学习包含于迁移学习,迁移学习可以解决其面临的没有数据的问题,然后利用多种现有的方法对其进行学习。
四.参考文献
[1]Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
[2]Transductive Multi-View Zero-Shot Learning.
[3]Hubness and Pollution: Delving into Class-Space Mapping for Zero-Shot Learning.
[4]Ridge Regression, Hubness, and Zero-Shot Learning.
[5]Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Network.