一.强化学习(Reinforcement Learning)
1.Introduction
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。
综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
- 策略(Policy):环境的感知状态到行动的映射方式。
- 反馈(Reward):环境对智能体行动的反馈。
- 价值函数(Value Function):评估状态的价值函数,状态的价值即从当前状态开始期望在未来获得的奖赏。
- 环境模型(Model):模拟环境的行为。
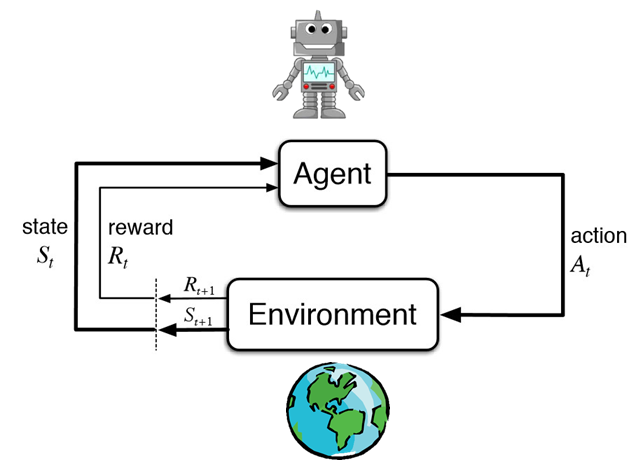
根据上图,agent(智能体)在进行某个任务时,首先与environment进行交互,产生新的状态state,同时环境给出奖励reward,如此循环下去,agent和environment不断交互产生更多新的数据。强化学习算法就是通过一系列动作策略与环境交互,产生新的数据,再利用新的数据去修改自身的动作策略,经过数次迭代后,agent就会学习到完成任务所需要的动作策略。
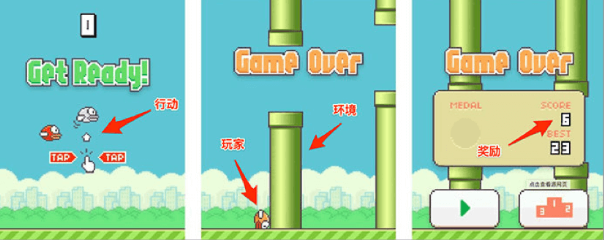
在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励。这就是一个典型的强化学习场景:
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励
2. Methods
主要有两种算法:免模型学习(Model-Free) vs 有模型学习(Model-Based)
在介绍详细算法之前,我们先来了解一下强化学习算法的2大分类。这2个分类的重要差异是:智能体是否能完整了解或学习到所在环境的模型
有模型学习(Model-Based)对环境有提前的认知,可以提前考虑规划,但是缺点是如果模型跟真实世界不一致,那么在实际使用场景下会表现的不好。
免模型学习(Model-Free)放弃了模型学习,在效率上不如前者,但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。
2.1 免模型学习 – 策略优化(Policy Optimization
| 这个系列的方法将策略显示表示为:  。 它们直接对性能目标  进行梯度下降进行优化,或者间接地,对性能目标的局部近似函数进行优化。优化基本都是基于 同策略 的,也就是说每一步更新只会用最新的策略执行时采集到的数据。策略优化通常还包括学习出 进行梯度下降进行优化,或者间接地,对性能目标的局部近似函数进行优化。优化基本都是基于 同策略 的,也就是说每一步更新只会用最新的策略执行时采集到的数据。策略优化通常还包括学习出  ,作为 ,作为  的近似,该函数用于确定如何更新策略。 的近似,该函数用于确定如何更新策略。 |
基于策略优化的方法举例:
2.2 免模型学习 – Q-Learning
这个系列的算法学习最优行动值函数  的近似函数:
的近似函数:  。它们通常使用基于 贝尔曼方程 的目标函数。优化过程属于 异策略 系列,这意味着每次更新可以使用任意时间点的训练数据,不管获取数据时智能体选择如何探索环境。对应的策略是通过
。它们通常使用基于 贝尔曼方程 的目标函数。优化过程属于 异策略 系列,这意味着每次更新可以使用任意时间点的训练数据,不管获取数据时智能体选择如何探索环境。对应的策略是通过  and
and  之间的联系得到的。智能体的行动由下面的式子给出:
之间的联系得到的。智能体的行动由下面的式子给出:

基于 Q-Learning 的方法
2.3 有模型学习 – 纯规划
这种最基础的方法,从来不显示的表示策略,而是纯使用规划技术来选择行动,例如 模型预测控制 (model-predictive control, MPC)。在模型预测控制中,智能体每次观察环境的时候,都会计算得到一个对于当前模型最优的规划,这里的规划指的是未来一个固定时间段内,智能体会采取的所有行动(通过学习值函数,规划算法可能会考虑到超出范围的未来奖励)。智能体先执行规划的第一个行动,然后立即舍弃规划的剩余部分。每次准备和环境进行互动时,它会计算出一个新的规划,从而避免执行小于规划范围的规划给出的行动。
- MBMF 在一些深度强化学习的标准基准任务上,基于学习到的环境模型进行模型预测控制
2.4 有模型学习 – Expert Iteration
| 纯规划的后来之作,使用、学习策略的显示表示形式:  。智能体在模型中应用了一种规划算法,类似蒙特卡洛树搜索(Monte Carlo Tree Search),通过对当前策略进行采样生成规划的候选行为。这种算法得到的行动比策略本身生成的要好,所以相对于策略来说,它是“专家”。随后更新策略,以产生更类似于规划算法输出的行动。 |
3. Application
3.1 Games
2016年:AlphaGo Master 击败李世石,使用强化学习的 AlphaGo Zero 仅花了40天时间,就击败了自己的前辈 AlphaGo Master。
《被科学家誉为「世界壮举」的AlphaGo Zero, 对普通人意味着什么?》
2019年1月25日:AlphaStar 在《星际争霸2》中以 10:1 击败了人类顶级职业玩家。
《星际争霸2人类1:10输给AI!DeepMind “AlphaStar”进化神速》
2019年4月13日:OpenAI 在《Dota2》的比赛中战胜了人类世界冠军。
《2:0!Dota2世界冠军OG,被OpenAI按在地上摩擦》
3.2 Robots
机器人很像强化学习里的「代理」,在机器人领域,强化学习也可以发挥巨大的作用。
《伯克利强化学习新研究:机器人只用几分钟随机数据就能学会轨迹跟踪》
二.深度强化学习(Deep Reinforcement Learning)
1.Introduction
传统的强化学习局限于动作空间和样本空间都很小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。当输入数据为图像,声音时,往往具有很高维度,传统的强化学习很难处理,深度强化学习就是把深度学习对于的高维输入与强化学习结合起来。
### 2. Methods
2.1 DQN
2013和2015年DeepMind的Deep Q Network(DQN)可谓是将两者成功结合的开端,它用一个深度网络代表价值函数,依据强化学习中的Q-Learning,为深度网络提供目标值,对网络不断更新直至收敛
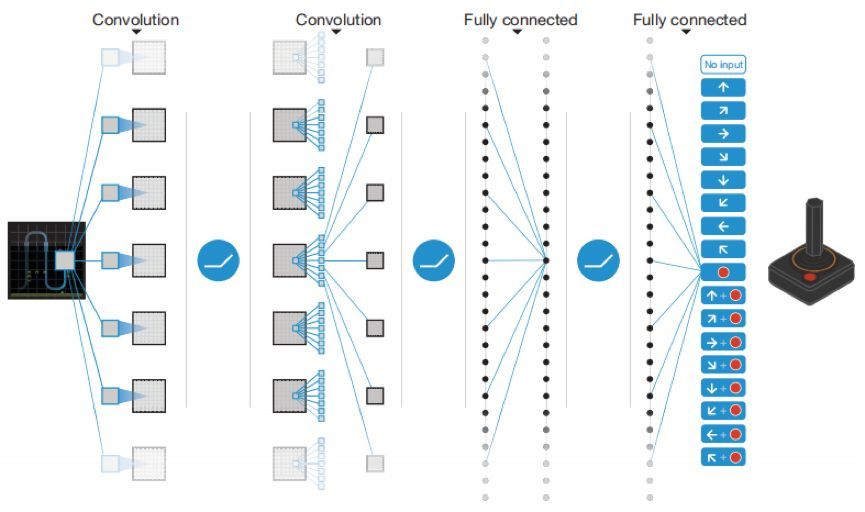
DQN用到了两个关键技术涉及到了两个关键技术:
1、样本池(Experience Reply):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(Fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
DQN在Atari games上用原始像素图片作为状态达到甚至超越人类专家的表现、通过左右互搏(self-play)等方式在围棋上碾压人类、大大降低了谷歌能源中心的能耗等等。当然DQN也有缺点,它是高维输入,低维输出的,当涉及到一次性输出连续动作时,即高维度输出,就束手无策了,DeepMind也在后续提出了DDPG。
3.Application
- 推荐系统
- 智能语音问答系统
- 无人驾驶
三.区别与联系
综上所述,深度强化学习是强化学习结合了深度学习而延伸出的概念。
深度学习则主要是以神经网络增加隐层个数而形成深度神经网络来进行学习,它在学习时,学习的数据和环境都是已知的,所以只需学习如何去拟合函数就可以了。
强化学习有agent、environment、reward、action等组成部分,就是一个智能体(agent)在一个未知的环境(environment)中,不断摸索,将动作(action)作用于环境,环境反馈奖励(reward)给智能体,然后智能体根据奖励来更新这个产生动作的决策函数。
深度强化学习是指:当环境越来越复杂,这个决策函数进行决策和实现起来就越来越困难,而深度神经网络正好具有强大的拟合能力,所以可以将这个决策函数用深度神经网络来代替,这样就形成了深度强化学习。
四.参考文献
[1] Sutton, R. & Barto, A. Reinforcement Learning: An Introduction (MIT Press, 1998).
[2] Richard Sutton. Learning to predict by the methods of temporal differences. Machine Learning. 3 (1): 9-44.1988.
[3] Christopher JCH Watkins and Peter Dayan. Q-learning. Machine learning, 8(3-4):279–292, 1992.
[4] Gerald Tesauro. Temporal difference learning and td-gammon. Communications of the ACM,
38(3):58–68, 1995.
[5] Tsitsiklis J N, Van R B. An analysis of temporal-difference learning with function approximation. IEEE Transactions on Automatic Control, 1997, 42(5): 674-690